
什么是液晶屏字模?字模又與顯示有什么關(guān)系?
我們大家應(yīng)該都知道,計(jì)算機(jī)所處理的是0、1代碼串形式的一些信息,那么計(jì)算機(jī)對于文字信息,它到底是如何處理的呢?這就涉及到了如何解決用0、1代碼串來表示文字符號的問題了,也就是其編碼的問題。在單片湘L系統(tǒng)之中漢字的編碼都是采用的字模來完成的。描述一個(gè)漢字點(diǎn)陣信息的二進(jìn)制代碼串稱為漢字的“字模”。所有的漢字以及各種符號的點(diǎn)陣信息就組成了漢字的“字模庫”(簡稱為字庫)。計(jì)算機(jī)在進(jìn)行輸出的時(shí)候,進(jìn)行處理的代碼必須要轉(zhuǎn)換成為相應(yīng)的字符的點(diǎn)陣形狀,以便于顯示以及打印,那么計(jì)算機(jī)就必須要存儲每一個(gè)字符的點(diǎn)陣信息。這一些點(diǎn)陣信息也就構(gòu)成了“字模庫”。比如:“A”這個(gè)字符。如果要進(jìn)行輸出,就必須在字模庫之中調(diào)用點(diǎn)陣信息,如圖所示。.
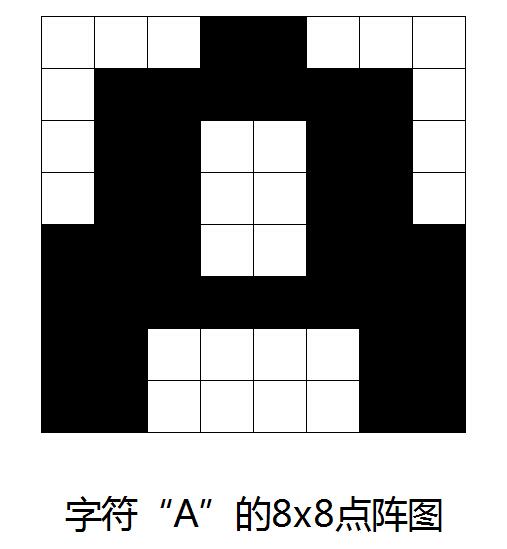
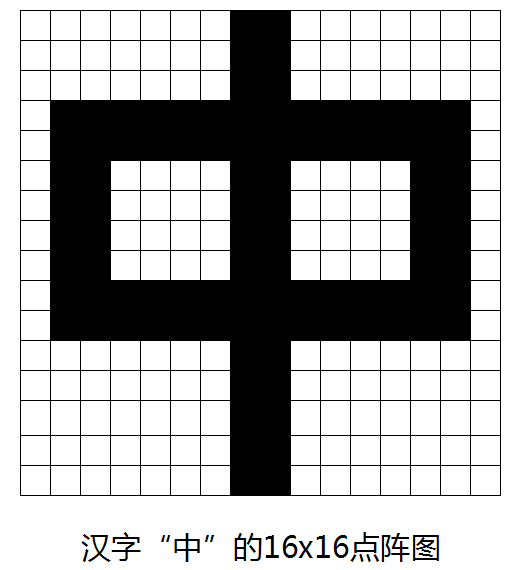
液晶顯示模塊字模的點(diǎn)陣數(shù)越大,字形也就更加好看,但是占用的存儲空間也越大。比如一個(gè)8X8的點(diǎn)陣字模占的字節(jié)數(shù)是8個(gè)字節(jié)。而一個(gè)16X16的點(diǎn)陣字模占的字節(jié)數(shù)是32個(gè)字節(jié)。通常一般的點(diǎn)陣類型有16X16、32X32、48X48等等。漢字的處理過程和英文的處理過程相類似,不過,由于其漢字信息的特點(diǎn)有所不同,必須要考慮和英文信息處理系統(tǒng)的兼容性,處理的難度也就更大。漢字的輸出主要還是指的漢字字形的輸出。輸出的方式主要還是顯示以及打印這兩種。漢字輸出的時(shí)候,用一個(gè)點(diǎn)陣來表示其中一個(gè)漢字。點(diǎn)陣的每一個(gè)點(diǎn)位都只有兩種狀態(tài):有點(diǎn)以及無點(diǎn)。如果用二進(jìn)制的代碼來表示,即為該位取值為1表示有點(diǎn),取值為0則表示無點(diǎn)。漢字的輸出原理和西文的輸出原理都是相同的。唯一不同的是漢字筆劃比較多,如果要能很好的表示出一個(gè)漢字,起碼也需要16X16的點(diǎn)陣才行。如果要求其字型逼真而且美觀,點(diǎn)陣的點(diǎn)數(shù)則還要繼續(xù)增加。如用24X24、32X32、48X48等,因此漢字的存儲空間也會比西文的要大很多,需要使用大量的存儲空間來存放中文字模。圖3.4.2.1.2是漢字“中”,使用的16X16點(diǎn)陣表示。
上一篇:lcm是什么意思?



